Un guide pour comprendre et évaluer les études sur l’analyse d’images médicales assistée par l’intelligence artificielle
Les nouvelles technologies basées sur l’apprentissage profond (deep learning), une sous discipline de l’Intelligence artificielle (IA), s’intègrent progressivement dans la pratique clinique des médecins, notamment pour l’analyse d’images médicales à des fins de diagnostic. Cependant, garantir l’efficacité et la fiabilité de ces outils diagnostiques repose sur la possibilité d’une évaluation rigoureuse des méthodes de développement et d’évaluation des modèles. Mais la complexité de la littérature dans le champ de l’IA rend souvent difficile la compréhension et la critique des études pour les cliniciens, qui sont actuellement peu formés à l’IA. Pour répondre à ce besoin, le Pr Jérémie Cohen, en collaboration avec un groupe de travail international, publie un guide de lecture dans le British Medical Journal. Ce guide à vocation à aider les cliniciens, chercheurs et décideurs de santé publique à évaluer la qualité des études qui utilisent l’apprentissage profond pour l’analyse d’images à visée diagnostique.
Dans une première partie, les auteurs expliquent de manière accessible les principes fondamentaux des réseaux de neurones convolutifs, les modèles d’IA les plus largement utilisés dans les dispositifs médicaux d’analyse d’images basés sur l’apprentissage profond. Cette approche donne aux lecteurs les clés pour comprendre les études publiées dans le domaine.
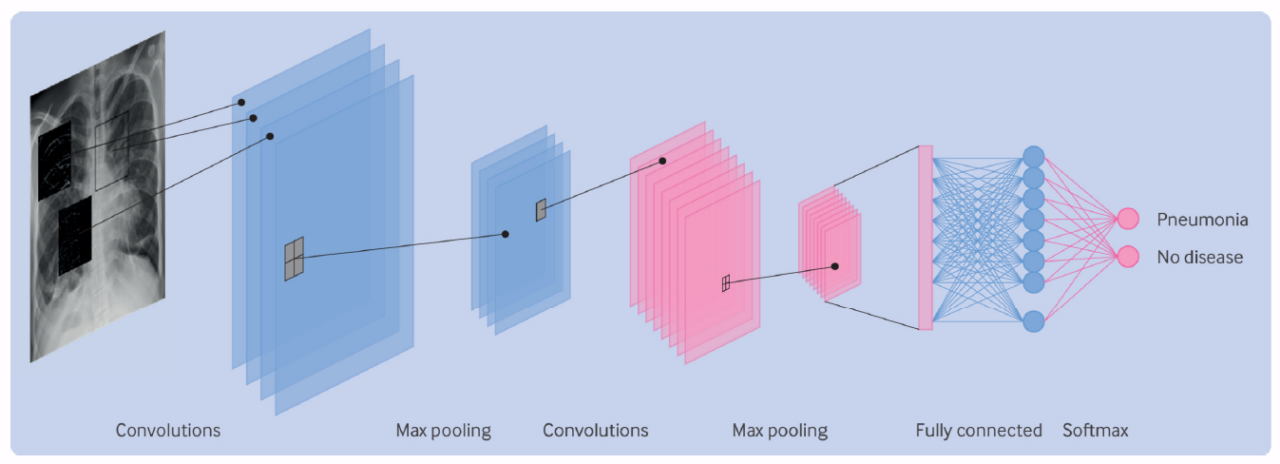
Dans une deuxième partie, les auteurs proposent une grille de lecture critique d’article en 20 points s’articulant autour de plusieurs thèmes-clés, chacun visant à répondre aux enjeux spécifiques de l’utilisation de l’apprentissage profond en médecine. Parmi les éléments importants de la grille figurent la nécessité de s’assurer de la pertinence clinique de la technologie (intérêt pour la pathologie ciblée et intégration dans le parcours de soin), de la qualité des données utilisées pour l’entraînement des modèles et de la robustesse du test de référence. Les auteurs soulignent également l’importance de validations externes évaluant les modèles sur des données cliniques réelles jamais rencontrées au cours de leur entrainement, et sur la nécessité de comparer les performances des modèles à celles d’outils diagnostiques déjà utilisés en routine.
Enfin, les auteurs illustrent les différents points de leur grille de lecture à travers 4 études cliniques utilisant l’apprentissage profond en pédiatrie : détection des otites sur des images otoscopiques, détection de fracture et de pneumonie sur des radiographies, et analyse automatique de photographies de visage pour aider au diagnostic de certaines maladies génétiques.
Au-delà des aspects méthodologiques, les chercheurs rappellent que l’adoption de l’IA en médecine doit reposer sur des standards éthiques rigoureux. Il est notamment essentiel de s’assurer que les IA n’aggravent pas les inégalités d’accès aux soins et les erreurs diagnostiques, des risques potentiels si certaines populations sont sous-représentées dans les bases de données qui servent à entraîner les modèles.
Ainsi, les chercheurs proposent un guide de lecture largement accessible, afin que les cliniciens et relecteurs des études évaluant les performances de modèles d’apprentissage profond se familiarisent avec cette littérature nouvelle et souvent complexe.
Par Jérémie Cohen
Lien vers l’article complet : https://www.bmj.com/content/387/bmj-2023-076703